The core concepts every Platform Engineer must know, explained in plain English.
Site Reliability Engineering can feel like alphabet soup. We drown in acronyms. But if you strip away the jargon, the discipline is built on just a few foundational blocks. Here are the core concepts of SRE, distilled.
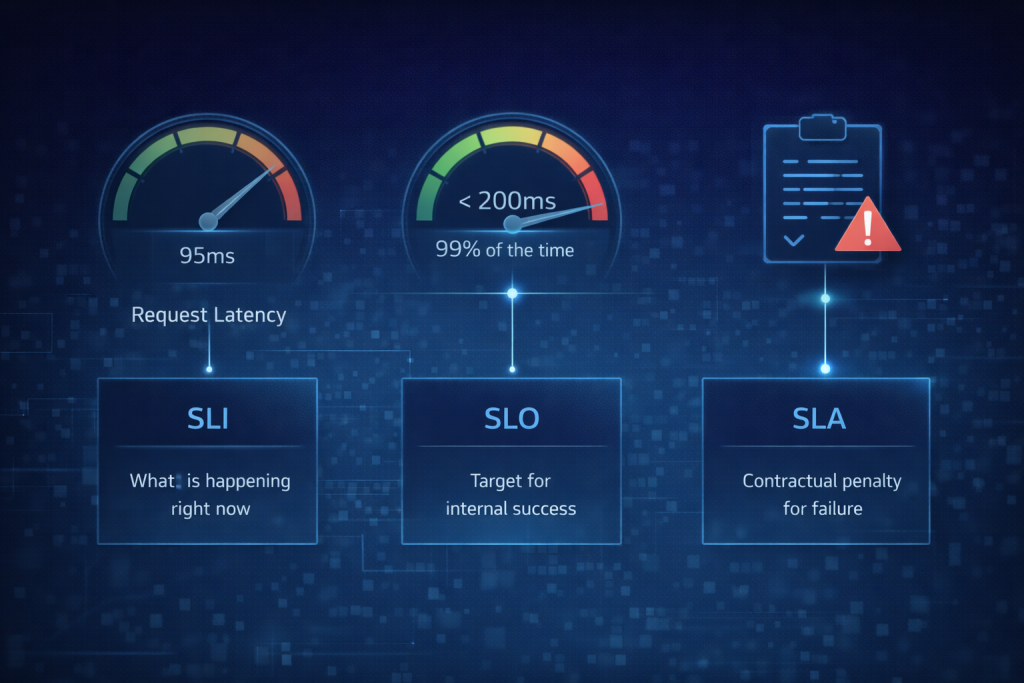
1. The Metrics (Measuring Success)
SLI (Service Level Indicator) The specific metric you are measuring to judge health (e.g., “Request Latency”). It is the needle on the dashboard that tells you what is happening right now.
SLO (Service Level Objective) The target value you aim for to keep users happy (e.g., “99.0% of requests must be faster than 200ms”). It is the internal goalpost that defines “Good” vs “Bad” performance.
SLA (Service Level Agreement) The external contract with users that defines the penalty if you fail (e.g., “If uptime drops below 99%, we refund you 10%”). It is the legal/financial safety net; SREs care about SLOs, lawyers care about SLAs.
Error Budget The amount of “allowable unreliability” you have left before you must freeze changes. It frames failure as a resource: if you have budget left, you can take risks; if you are bankrupt, you prioritize stability.
2. The Work (Operational Reality)
Toil Work that is manual, repetitive, tactical, devoid of enduring value, and scales linearly with service growth. It is the “grunt work” (like manually restarting servers) that SREs strive to automate out of existence.
Observability The ability to understand the internal state of a system based solely on its external outputs (logs, metrics, traces). Monitoring tells you that the system is broken; Observability allows you to ask why it is broken.
Capacity Planning The process of forecasting future resource usage to ensure the system can handle growth without crashing. It is the art of buying enough servers to survive Black Friday, but not so many that you burn money.
3. The Culture (Human Factors)
Blameless Post-Mortem An incident review process focused on identifying systemic causes rather than blaming individuals. We don’t fire the engineer who pushed the bad code; we fix the pipeline that allowed bad code to be pushed.
Chaos Engineering The practice of intentionally injecting failure into a system (e.g., killing a database node) to test resilience. It is better to break the system yourself at 2 PM on a Tuesday than to let it break itself at 3 AM on a Sunday.
Incident Command System (ICS) A framework for emergency management that assigns clear roles (Commander, Scribe, Ops Lead) during an outage. It prevents the “too many cooks in the kitchen” problem when the site is down.
(Conclusion)
These concepts are not just vocabulary words; they are the primitives we use to build reliable systems. If you can master the difference between an SLO and an SLA, and identify Toil when you see it, you are already thinking like an SRE.
Leave a Reply